来源:芝能汽车
在AI训练与GPU集群驱动的算力革命中,存储架构正迎来深刻重塑,Meta提出的E2外形规格,成为这一变革的核心引擎。
它以1PB级QLC固态硬盘为目标,通过优化封装布局与散热结构,突破了E1与E3标准的容量瓶颈,构建出真正面向GPU规模计算的存储体系。
Part 1
E2:
从QLC堆叠到GPU集群的能效平衡
存储的演进,本质上是数据密度、功耗与结构之间的长期博弈。
Meta推动E2标准,是因为现有的E1、E3外形规格在面对超大容量QLC NAND时已显得力不从心。随着生成式AI、LLM训练与多模态模型对数据吞吐的需求持续增长,GPU服务器成为新的计算基石,而存储架构却逐渐成为瓶颈。
E2的出现,正是为了让存储单元与GPU计算单元在功耗、密度与可扩展性上实现新的平衡。
QLC(Quad-Level Cell)技术是E2实现1PB目标的基础。与TLC相比,QLC每个单元存储四个比特,提高了单位面积存储密度。
带来的问题也同样突出:写入寿命缩短、延迟增加、散热困难等。
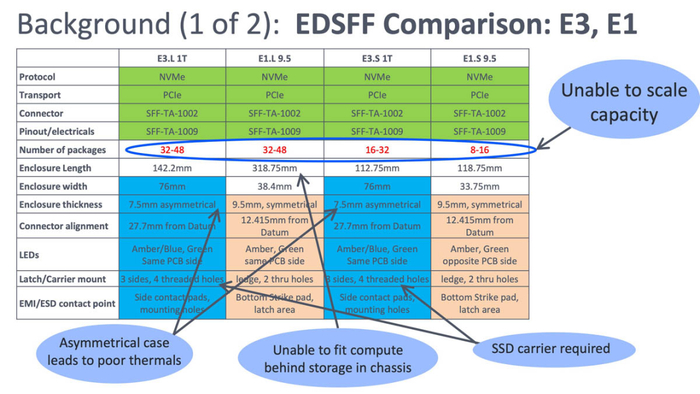
E1.S与E3.L等现有标准虽已支持QLC产品,但在堆叠密度与功耗控制上受限明显。E3.L的非对称外壳导致散热路径受限,而E1.S在封装数量与功耗余量上都无法支持超过128TB的容量。
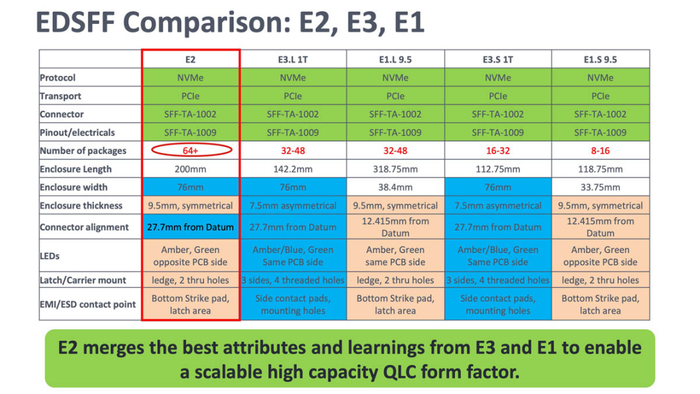
Meta工程团队因此设计了E2外形,以200mm × 76mm × 9.5mm的对称封装尺寸重新定义布局逻辑,使其能够容纳64个以上的NAND封装,同时保持高效的热管理结构。

E2仍采用标准化的EDSFF(Enterprise & Datacenter SSD Form Factor)接口,与现有PCIe Gen5 NVMe协议完全兼容。这意味着它可以无缝集成到现有服务器背板系统中,而无需改变基础互联结构。
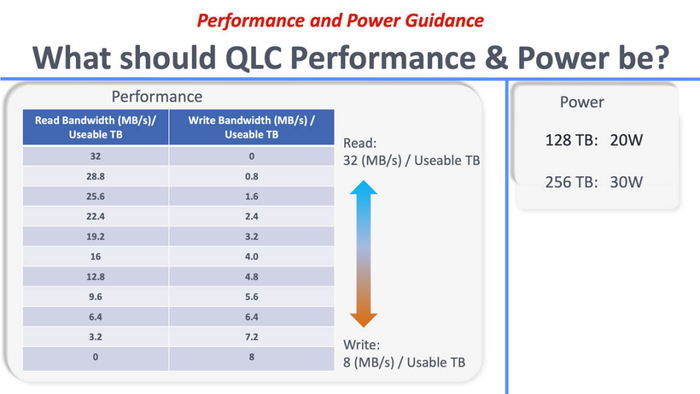
更关键的是,E2的功耗控制目标被限定在80W以内,即便在1PB容量下也能保持能效比优势。
Meta已经在一台搭载40块E2 SSD的原型机中完成演示——单台服务器即可实现40PB的存储容量,总功耗约3.2kW。
这一数据意味着,每PB存储的系统能耗将下降约30%,同时显著减少了CPU与NIC的配置需求,从而在服务器层面提升整体计算密度与能效。
从系统角度看,E2的意义在于架构的一致性。
过去,GPU服务器往往依赖分层式存储结构:高速NVMe用于训练缓存,大容量SATA或HDD用于冷数据。这种结构导致数据流转复杂、延迟高且难以管理。
E2所代表的1PB级QLC SSD,则有可能直接承担热数据存储与模型缓存功能,让GPU与存储之间形成高带宽、低延迟的直接访问通道。这为AI训练带来一种全新的架构可能性——计算与数据的同域共存。
从制造工艺角度看,E2的实现同样得益于NAND封装技术的演进。
当前主流的176层与232层堆叠NAND已能在单颗Die上实现高达2Tb的容量,而通过堆叠封装与更高密度的BGA布局,单PCB即可支持上千颗NAND芯片。
这一能力,加上高效的散热路径与热均衡管理,使E2能够在高密度运行下维持稳定性能。
Meta提出的“每TB性能调优”策略,正是基于QLC特性,通过控制读写比与访问频率,实现能效与性能的最佳平衡。
Part 2
E2推动的计算-存储融合
E2是系统工程思维下的必然产物,AI基础设施设计范式的转变——从以CPU为中心的存储系统,走向以GPU为核心的“计算密集+数据密集”融合系统。
在传统数据中心中,存储与计算是分离的。NVMe SSD的任务是为CPU提供低延迟数据访问,而GPU通常从中间层或缓存节点加载数据。随着大模型训练规模爆炸式增长,这种分离架构导致存储I/O成为系统性能的瓶颈。
GPU集群需要持续流动的高带宽数据,而CPU层的缓存和调度反而成了“堵点”。
E2正是为了解决这一问题而生:它以更高的存储密度、更低的能耗和更简单的物理布局,让数据中心可以在同一机架内部署PB级存储容量,实现“GPU直连存储”的可能。
这个关键趋势是减少控制器与互联资源的重复配置。
在传统架构中,每提升存储容量,就必须同步增加控制器与网络接口数量,从而推高能耗与系统复杂性。
而E2通过极端容量提升,实现“同CPU、同NIC下的更高PB密度”,使系统在单位能耗下能支撑更多数据负载。这种“控制器均摊效应”不仅降低了设备成本,也直接推动了算力基础设施的绿色化。
E2的出现将对现有存储生态产生深远影响。
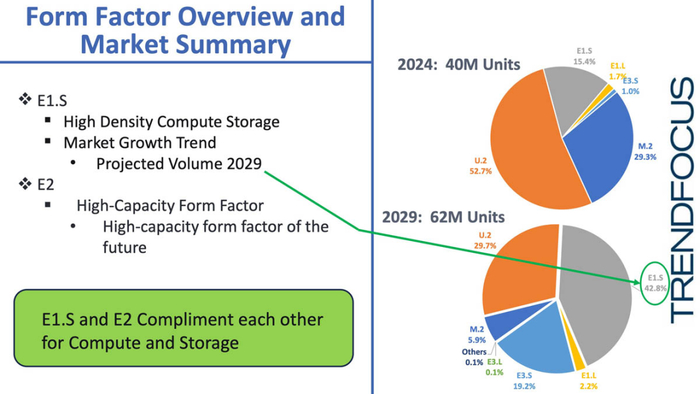
2024年M.2 SSD市场出货量预计将骤降至原有的五分之一,主要原因正是其容量受限与散热瓶颈,E1.S与E2的份额将持续上升,特别是E1.S将在高性能计算节点中占据主导.
而E2则成为企业级与AI训练集群的主流存储形态,U.2形态的总容量预计在2029年前仍将高于E3与E1系列总和,在过渡阶段仍需兼容传统规格。
E2的成功还取决于整个产业链的配合。
控制器厂商需优化QLC写入算法与纠错机制,确保在高容量、高热密度环境下的可靠性。NAND制造商则需继续推进更高层数堆叠与能效改进,以支撑1PB级产品的商业化。
散热与结构材料的创新也将成为关键。
E2外壳的热优化设计意味着更高的导热系数材料、更高效的气流路径,以及对服务器风道的重新规划。Meta在其样机中通过单PCB与热对称外壳实现了25W以上散热能力,这为后续80W级功耗下的长期稳定运行奠定了基础。
存储不再只是“数据容器”,而成为算力的一部分。
当GPU需要访问PB级训练数据时,不再受限于传统的网络瓶颈与分层调度,而是可以像调用显存一样直接调用SSD数据块。
未来,在CXL(Compute Express Link)互联架构的支持下,E2甚至有可能成为计算与存储共享内存的一部分,彻底打破二者的界限。

过去分层式、模块化的存储架构,转化为面向算力需求的整体性平台,在GPU为中心的计算环境下,存储必须以更高密度、更高能效和更低延迟的形式嵌入计算体系中。
未来十年数据中心的结构方向:统一接口、极致容量、模块化扩展和智能能耗控制。
特别声明:以上内容仅代表作者本人的观点或立场,不代表新浪财经头条的观点或立场。如因作品内容、版权或其他问题需要与新浪财经头条联系的,请于上述内容发布后的30天内进行。